Funkcjonowanie silników wyszukiwania pełnotekstowego (np. SphinxSearch) opiera się na dwóch specjalizowanych procesach: indeksującym dokumenty (indekser) oraz umożliwiającym wyszukiwanie. Jednak do prawidłowego działania wyszukiwania niezbędny jest indeks będący efektem procesu indeksowania. Dane w takim indeksie zorganizowane są w postaci tzw. indeksu odwróconego czyli struktury danych zawierającej identyfikatory dokumentów oraz pozycję, na której dany token się znajduje. Przechowywanie danych w ten sposób umożliwia bardzo szybkie wyszukiwanie - znając szukaną frazę / tokeny od razu mamy przyporządkowane dokumenty zawierające te wyrażenia.
Inverted index
Przykładowo mamy dokumenty zawierające:
- doc_id=1 : The quick brown fox jumped over the lazy dog
- doc_id=2 : Quick <i>brown</i> foxes leap over lazy <b>dogs</b> in summer
które zostaną odwzorowane w indeksie w następujący sposób:
| The | {doc_id=1, pos=1} |
| quick | {doc_id=1, pos=2} |
| brown | {doc_id=1, pos=3} {doc_id=2, pos=2} |
| fox | {doc_id=1, pos=4} |
| jumped | {doc_id=1, pos=5} |
| over | {doc_id=1, pos=6} {doc_id=2, pos=5} |
| the | {doc_id=1, pos=7} |
| lazy | {doc_id=1, pos=8} {doc_id=2, pos=6} |
| dog | {doc_id=1, pos=9} |
| Quick | {doc_id=2, pos=1} |
| foxes | {doc_id=2, pos=3} |
| leap | {doc_id=2, pos=4} |
| dogs | {doc_id=2, pos=7} |
| in | {doc_id=2, pos=8} |
| summer | {doc_id=2, pos=9} |
Tokeny
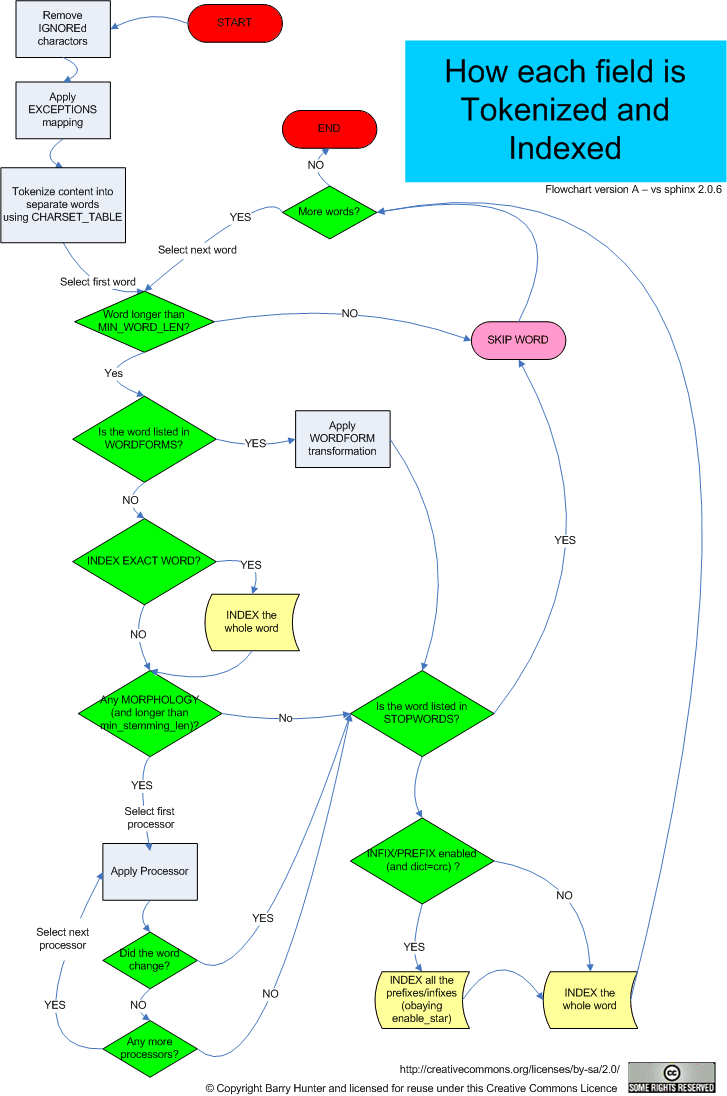
Wyrażenia w lewej kolumnie to tokeny, czyli pojedyncze jednostki lingwistyczne (np. słowa, liczby, daty, kwoty, adresy IP, adresy email itd.), które mogą zostać wyodrębnione z tekstu źródłowego. W dużym skrócie indeksowanie sprowadza się właśnie do wyodrębniania oraz przetwarzania wspomnianych tokenów, tak aby na tej podstawie można było zbudować inverted index. Proces ten (indeksowanie) jest bardzo złożony - nie sprowadza się wyłącznie do tokenizacji (rozbicia na tokeny), ale także usuwane są tagi HTMLowe, stopwords, tokeny sprowadzane są do postaci bazowej itd. Bardzo dobrze ilustruje to następujący schemat:

(źródło: sphinxsearch.com)
Poszczególne kroki przedstawione na tym schemacie zostały opisane na blogu Sphinxa.
Wracając do przytoczonego powyżej odwzorowania tekstów (z przykładowych dokumentów) na tokeny w odwróconym indeksie, w kolejnych etapach indeksowania, po usunięciu tagów HTMLowych i wyodrębnieniu tokenów, ich lista zostanie ograniczona, np. zamiana wielkich liter na małe, usuwanie stopwords, sprowadzanie form w liczbie mnogiej do pojedynczej (np. foxes - fox), ewentualne synonimy (np. leap - jump) itd. Zatem, finalnie nasz indeks odwrócony będzie postaci:
| brown | {doc_id=1, pos=3} {doc_id=2, pos=2} |
| dog | {doc_id=1, pos=9} {doc_id=2, pos=7} |
| fox | {doc_id=1, pos=4} {doc_id=2, pos=3} |
| in | {doc_id=2, pos=8} |
| jump | {doc_id=1, pos=5} {doc_id=2, pos=4} |
| lazy | {doc_id=1, pos=8} {doc_id=2, pos=6} |
| over | {doc_id=1, pos=6} {doc_id=2, pos=5} |
| quick | {doc_id=1, pos=2} {doc_id=2, pos=1} |
| summer | {doc_id=2, pos=9} |
Stopwords, wordforms, morphology
Uwzględniając wszystkie te etapy procesu indeksowania przez SphinxSearch, przykładowa konfiguracja wygląda następująco:
#############################################################################
## index definition
#############################################################################
index test_indexer_stemmer
{
source = src1
path = /var/lib/sphinxsearch/data/test_indexer
min_word_len = 2
morphology = stem_en
min_stemming_len = 2
wordforms = /etc/sphinxsearch/synonyms.txt
stopwords = /etc/sphinxsearch/stopwords.txt
}Proponowana konfiguracja zawiera takie elementy jak stopwords, wordforms oraz morphology.
Stopwords to wyrażenia nieistotne, nie mające żadnej albo niewielką wartość informacyjną podczas wyszukiwania. Przykładami mogą być the, a, an dla języka angielskiego. Wyrażenia takie nie zostaną zaindeksowane, natomiast podczas wyszukiwania zostaną pominięte w wyszukiwanej frazie.
Pod pojęciem wordforms, w przypadku SphinxSearch, należy rozumieć pewnego rodzaju słownik zawierający przekształcenia jednych wyrażeń na drugie. W ten sposób możemy dostarczyć dla indeksera słownik synonimów, np. leap - jump, s02e01 - season 2 episode 1 itd. Indeksując wyrażenie, dla którego definiujemy inną formę (np. synonim) będzie ono reprezentowane (w indeksie) jako ta nowa forma, szukając - słowa z szukanej frazy także zostaną zamienione na zmapowaną formę wyrażenia.
Morphology definiuje listę użytych preprocesorów które zostaną wykorzystane do przetworzenia tokenów, do których możemy zaliczyć m.in lematyzery i stemmery. Więcej informacji odnośnie wykorzystania lemmatyzerów i stemmerów możecie znaleźć w jednym z moich poprzednich artykułów oraz na oficjalnym blogu SphinxSearch. Dzięki tej opcji możemy uzyskać sprowadzenie tokenów w liczbie mnogiej do pojedynczej czy też ich do formy bazowej, np. foxes - fox, jumped - jump itd. SphinxSearch jest pod tym względem (lematyzacja, stemming) cały czas rozwijany i sukcesywnie dodawane są kolejne preprocesory. Wykorzystany w załączonym przykładzie stemmer (stem_en) to tzw. Porter’s English stemmer. Niestety nie jest to rozwiązanie idealne i zdarzają się nie zawsze poprawne przekształcenia, np. lazy - lazi. Niedociągnięcia takie możemy korygować za pomocą wordforms, z tym że należy mieć na uwadze kolejność etapów podczas indeksowania. Jeśli spojrzymy na przedstawiony schemat z kolejnymi krokami, zauważymy że wordforms są wykonywane przed morphology. Możemy jednak skorzystać z faktu, iż etap Post-Morphology Wordforms wykonywany jest po morphology - do pliku zawierającego wordforms dodajemy przekształcenie interesującego nas wyrażenia poprzedzając oryginalne wyrażenie znakim ~, np. ~lazy > lazy. W ten sposób osiągniemy nasz cel, czyli skorygujemy nieprawidłowe przekształcenia stemmera. Ostatecznie, zaindeksowane zostanie słowo lazy, nawet pomimo przekształcenia go na lazi przez stemmer Portera. Alternatywą dla użycia stemmera Portera oraz dodatkowej korekty za pomocą wordforms może być wykorzystanie lematyzera języka angielskiego - tam nie występują dziwne formy bazowe wyrażeń. Efekt końcowy będzie identyczny, tyle że sam proces indeksowania będzie nieco prostszy.
Alternatywna konfiguracja:
#############################################################################
## index definition
#############################################################################
index test_indexer_lemmatizer
{
source = src1
path = /var/lib/sphinxsearch/data/test_indexer_lemmatizer
min_word_len = 2
morphology = lemmatize_en_all
stopwords = /etc/sphinxsearch/stopwords.txt
} Zweryfikujmy zatem jak ostatecznie wygląda po stronie naszego silnika wyszukiwawczego:
sphinxQL> CALL KEYWORDS('The quick brown fox jumped over the lazy dog', 'test_indexer_stemmer');
+------+-----------+------------+
| qpos | tokenized | normalized |
+------+-----------+------------+
| 2 | quick | quick |
| 3 | brown | brown |
| 4 | fox | fox |
| 5 | jumped | jump |
| 6 | over | over |
| 8 | lazy | lazy |
| 9 | dog | dog |
+------+-----------+------------+
7 rows in set (0.00 sec) sphinxQL> CALL KEYWORDS('Quick <i>brown</i> foxes leap over <b>lazy</b> dogs in summer', 'test_indexer_stemmer');
+------+-----------+------------+
| qpos | tokenized | normalized |
+------+-----------+------------+
| 1 | quick | quick |
| 2 | brown | brown |
| 3 | foxes | fox |
| 4 | leap | jump |
| 5 | over | over |
| 6 | lazy | lazy |
| 7 | dogs | dog |
| 8 | in | in |
| 9 | summer | summer |
+------+-----------+------------+
9 rows in set (0.00 sec) Blend chars
Chciałbym zwrócić jeszcze uwagę na inną przydatną opcję podczas indeksowania i wyszukiwania. Domyślnie wszystkie znaki nie uwzględnione w charset_table traktowane są jako separatory. Może jednak pojawić się potrzeba wyszukiwania tokenów zawierających specyficzne znaki, jednocześnie traktując je jako separatory, np. frazę user@sphinxsearch.com chcielibyśmy rozbić na tokeny user, sphinxsearch.com oraz user@sphinxsearch.com. W takiej sytuacji skorzystamy z opcji blend_chars zawierającej znaki, które będą traktowane jako separatory oraz jednocześnie jako prawidłowe znaki. W przedstawionym przykładzie konfiguracja indeksu będzie wyglądała następująco:
#############################################################################
## index definition
#############################################################################
index test_blend_chars
{
source = src1
path = /var/lib/sphinxsearch/data/test_blend_chars
min_word_len = 1
charset_table = 0..9, A..Z->a..z, ., a..z
blend_chars = +, &, @, -, !
blend_mode = trim_head, trim_tail, trim_none
} Dodatkowo istnieje możliwość skonfigurowania w jaki sposób wyrażenie zawierające znaki określone jako blend_chars zostanie zaindeksowane (parametr konfiguracji blend_mode). Domyślnie zaindeksowany zostanie cały token, ale czasami będziemy potrzebowali innej reprezentacji. Przykładowo wyrażenie @sphinxsearch! będziemy potrzebowali w formie tokenów: @sphinxsearch, sphinxsearch!, @sphinxsearch! oraz sphinxsearch. Polegając na domyślnej konfiguracji uzyskamy wyłącznie tokeny @sphinxsearch! oraz sphinxsearch. Ustawiając tryby trim_head, trim_tail oraz trim_none osiągniemy postać jakiej oczekiwaliśmy.
sphinxQL> CALL KEYWORDS('@sphinxsearch! AT&T user@sphinxsearch.com', 'test_blend_chars');
+------+-----------------------+-----------------------+
| qpos | tokenized | normalized |
+------+-----------------------+-----------------------+
| 1 | @sphinxsearch! | @sphinxsearch! |
| 1 | sphinxsearch! | sphinxsearch! |
| 1 | @sphinxsearch | @sphinxsearch |
| 1 | sphinxsearch | sphinxsearch |
| 2 | at&t | at&t |
| 2 | at | at |
| 3 | t | t |
| 4 | user@sphinxsearch.com | user@sphinxsearch.com |
| 4 | user | user |
| 5 | sphinxsearch.com | sphinxsearch.com |
+------+-----------------------+-----------------------+
10 rows in set (0.00 sec) Pliki indeksu
Pliki indeksu zapisywane są przez SphinxSearch w kilku plikach o takiej nazwie jak nazwa indeksu, ale posiadających różne rozszerzenia. Każdy z nich pełni osobną funkcję:
- .spa - przechowuje wartości atrybutów, nie podlegają procesowi tokenizacji jak to ma miejsce w przypadku pól tekstowych (ang. fields)
- .spd - identyfikatory dokumentów (ang. doclist) przyporządkowanych do poszczególnych tokenów
- .sph - nagłówek indeksu zawierający m.in typy pól oraz atrybutów, ścieżka do pliku zawierającym stopwords itd.
- .spi - słownik zawierający wyodrębnione (z pól tekstowych) tokeny (ang. wordlist)
- .spk - kill list, czyli identyfikatory dokumentów wykluczonych z danych indeksów (przydatne podczas obsługi operacji typu delete / update bez konieczności przeindeksowania całości)
- .spl - locki zakładane na indeksy (ang. locks)
- .spm - wartości typu MVA (ang. multi-valued attributes)
- .spp - pozycja danego tokenu w indeksowanym tekście (ang. hitlist)
- .sps - atrybuty tekstowe
Szczegółowy opis poszczególnych elementów indeksu znajdziecie tutaj.
Ponadto przydatne może okazać się narzędzie (indextool) dostępne w pakiecie SphinxSearch pozwalające podejrzeć konfigurację, nagłówek czy też inne elementy indeksu. Najważniejsze opcje:
- –dumpconfig {index_name}.sph - podgląd konfiguracji indeksu
- –dumpheader {index_name}.sph - podgląd nagłówka indeksu
- –dumpdocids {index_name} - lista identyfikatorów dokumentów w indeksie
- –dumphitlist {index_name} {keyword} - lista identyfikatorów dokumentów wraz pozycją, w których dane słowo występuje
- –fold {index_name} {path_to_file} - weryfikacja jak wyrażenie z podanego pliku zostanie rozbite na tokeny
Alternatywą dla ostatniej z wymienionych powyżej opcji może być użycie CALL KEYWORDS({keywords}, {index_name}); z poziomu SphinxQL.
Indeksowanie dokumentów przez SphinxSearch jest wieloetapowym złożonym procesem. Wiedząc jakie operacje wykonywane są w danym kroku, możemy w pełni świadomy i wygodny dla nas sposób konfigurować indeks, tak aby odpowiadał naszym potrzebom. Dodatkowo dzięki dostępnym narzędziom będziemy w stanie przeanalizować na jakie tokeny rozbijany będzie indeksowany tekst, co znacznie ułatwia weryfikację czy dany dokument będzie pasował do szukanej frazy. W końcu, indextool może zostać wykorzystany do wyciągania informacji (konfiguracja, nagłówek, identyfikatory dokumentów) z plików indeksów. Zatem, udanego indeksowania!
Przydatne linki:
- http://en.wikipedia.org/wiki/Inverted_index
- http://rosettacode.org/wiki/Inverted_Index
- http://en.wikipedia.org/wiki/Search_engine_indexing
- http://www.ir.uwaterloo.ca/book/
- https://www.thunderstone.com/site/texisman/tokenization_and_inverted.html
- http://www.cs.sfu.ca/CourseCentral/456/jpei/web slides/L07 - Tokenization.pdf
- http://sphinxsearch.com/blog/2014/11/26/sphinx-text-processing-pipeline/
- http://www.ivinco.com/blog/sphinx-in-action-how-sphinx-handles-text-during-indexing/
- http://www.nearby.org.uk/sphinx/sphinx-tokenizing.gif
- http://sphinxsearch.com/blog/2014/12/04/how-to-use-the-wordforms-list/
- http://sphinxsearch.com/blog/2013/07/15/morphology-processing-with-sphinx/
- http://sphinxsearch.com/blog/2013/12/05/working-with-the-english-lemmatizer/
- http://search.blox.pl/2010/01/Myslec-po-polsku.html
- http://sphinxsearch.com/blog/2012/08/14/indexing-tips-tricks/
- http://www.ivinco.com/blog/how-to-improve-sphinx-indexing-performance/
- http://blog.stunf.com/building-a-scalable-real-time-search-architecture-with-sphinx/
- http://sphinxsearch.googlecode.com/svn/trunk/doc/internals-index-format.txt
- http://sphinxsearch.com/docs/current.html#confgroup-index
{kind=link}
tagi: indexer , lemmatization , morphology , search , sphinx , stemming , sphinxsearch